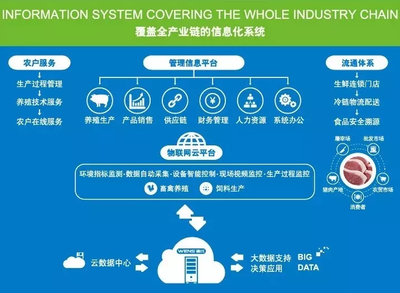
在傳統(tǒng)漁業(yè)向現(xiàn)代化轉(zhuǎn)型的浪潮中,智慧漁業(yè)正以其科技賦能、生態(tài)友好的特點(diǎn),成為推動(dòng)行業(yè)可持續(xù)發(fā)展的關(guān)鍵力量。其中,精準(zhǔn)的水質(zhì)監(jiān)測與科學(xué)的畜牧漁業(yè)飼料銷售,構(gòu)成了智慧漁業(yè)體系的兩大核心支柱,共同守護(hù)著寶貴的藍(lán)色生態(tài),并驅(qū)動(dòng)著整個(gè)產(chǎn)業(yè)鏈的提質(zhì)增效。
一、 智慧水質(zhì)監(jiān)測:藍(lán)色生態(tài)的“守望者”
水是魚類生存與生長的根本。傳統(tǒng)漁業(yè)依賴經(jīng)驗(yàn)判斷水質(zhì),存在反應(yīng)滯后、調(diào)控粗放等問題,極易導(dǎo)致水體惡化、病害爆發(fā),不僅造成經(jīng)濟(jì)損失,更對水域生態(tài)環(huán)境構(gòu)成威脅。智慧漁業(yè)通過部署物聯(lián)網(wǎng)傳感器網(wǎng)絡(luò),實(shí)現(xiàn)了對水溫、溶解氧、pH值、氨氮、亞硝酸鹽等關(guān)鍵水質(zhì)參數(shù)的24小時(shí)不間斷、實(shí)時(shí)在線監(jiān)測。
其核心價(jià)值在于:
1. 預(yù)警與防控: 系統(tǒng)可設(shè)定安全閾值,一旦數(shù)據(jù)異常即刻報(bào)警,使養(yǎng)殖者能迅速采取增氧、換水、調(diào)節(jié)pH等措施,將風(fēng)險(xiǎn)扼殺在萌芽狀態(tài),有效避免大面積死魚和生態(tài)災(zāi)難。
2. 數(shù)據(jù)驅(qū)動(dòng)決策: 長期監(jiān)測形成的水質(zhì)大數(shù)據(jù),有助于分析變化規(guī)律,為精準(zhǔn)投喂、密度控制、微生物制劑使用等提供科學(xué)依據(jù),實(shí)現(xiàn)從“經(jīng)驗(yàn)養(yǎng)魚”到“數(shù)據(jù)養(yǎng)魚”的跨越。
3. 生態(tài)保護(hù): 通過維持水體生態(tài)平衡,減少藥物濫用和過剩餌料污染,從根本上減輕養(yǎng)殖活動(dòng)對周邊水域的環(huán)境壓力,守護(hù)江河湖海的藍(lán)色生態(tài),踐行“綠水青山就是金山銀山”的理念。
二、 畜牧漁業(yè)飼料銷售:從“產(chǎn)品供應(yīng)”到“營養(yǎng)解決方案”
飼料是養(yǎng)殖成本的核心,其質(zhì)量與投喂策略直接關(guān)系到魚類健康、水質(zhì)狀況和最終產(chǎn)出。在智慧漁業(yè)框架下,飼料銷售不再是簡單的商品流通,而是升級(jí)為基于數(shù)據(jù)和服務(wù)的“精準(zhǔn)營養(yǎng)解決方案”。
新型飼料銷售模式的轉(zhuǎn)變體現(xiàn)在:
1. 與監(jiān)測數(shù)據(jù)聯(lián)動(dòng): 結(jié)合實(shí)時(shí)水質(zhì)與魚類生長監(jiān)測數(shù)據(jù),銷售商或服務(wù)商可以為養(yǎng)殖戶推薦最適配的飼料品種、投喂率和投喂時(shí)間。例如,在溶解氧較低的時(shí)段建議減少投喂,避免殘餌加劇耗氧與污染。
2. 產(chǎn)品專業(yè)化與環(huán)保化: 銷售更多高消化率、低氮磷排放的環(huán)保型飼料。這類飼料能最大化地被魚類吸收,顯著減少糞便中對水質(zhì)有害的氮、磷排放,從源頭助力水質(zhì)維護(hù)。
3. 服務(wù)鏈條延伸: 領(lǐng)先的飼料企業(yè)正轉(zhuǎn)型為綜合服務(wù)商,提供包括水質(zhì)檢測工具、投喂智能設(shè)備、養(yǎng)殖技術(shù)指導(dǎo)在內(nèi)的打包服務(wù)。飼料銷售成為切入點(diǎn)和抓手,深度綁定用戶,共同優(yōu)化養(yǎng)殖全程。
三、 協(xié)同賦能:構(gòu)建循環(huán)共生的智慧漁業(yè)生態(tài)
智慧水質(zhì)監(jiān)測與智慧化飼料銷售并非孤立存在,二者深度融合,形成了正向循環(huán)的產(chǎn)業(yè)生態(tài)閉環(huán):
- 以水定飼: 水質(zhì)數(shù)據(jù)指導(dǎo)科學(xué)投喂,避免過度投餌污染水體。
- 以飼護(hù)水: 優(yōu)質(zhì)環(huán)保飼料從源頭減少污染負(fù)荷,減輕水質(zhì)監(jiān)測系統(tǒng)的壓力,降低調(diào)水成本。
- 數(shù)據(jù)共享: 監(jiān)測數(shù)據(jù)反饋給飼料研發(fā)端,促使產(chǎn)品迭代更貼合健康養(yǎng)殖與生態(tài)保護(hù)需求。
這種協(xié)同最終實(shí)現(xiàn)了 “生態(tài)效益”與“經(jīng)濟(jì)效益”的統(tǒng)一:養(yǎng)殖水體更健康,魚類病害減少,品質(zhì)提升;飼料利用效率提高,成本更優(yōu);整體養(yǎng)殖模式環(huán)境友好,符合綠色高質(zhì)量發(fā)展方向。
****
智慧漁業(yè),以科技之眼守望水質(zhì),以創(chuàng)新之道升級(jí)飼喂。它不僅是監(jiān)測屏幕上的數(shù)據(jù)曲線,也不僅是飼料袋上的成分表,更是一套以數(shù)據(jù)為紐帶,聯(lián)通生態(tài)保護(hù)與產(chǎn)業(yè)效益的現(xiàn)代化生產(chǎn)管理體系。通過守護(hù)那一泓清澈的藍(lán)色生態(tài),并賦能從飼料到餐桌的每一個(gè)環(huán)節(jié),智慧漁業(yè)正在為我們描繪出一幅資源節(jié)約、環(huán)境友好、產(chǎn)品安全、產(chǎn)業(yè)高效的漁業(yè)發(fā)展新圖景,為保障糧食安全和水域生態(tài)安全貢獻(xiàn)著不可或缺的科技力量。